
Refactoring Impact Analysis
- List classes that will be impacted by the refactoring
- Visualize classes involved in the coupling between 2 projects
- Tranform your monolithic code into layered code
- Split god class into a grape of smaller classes
- How to Plan Large-Scale Refactoring?
- Clean Architecture Refactoring: A Case Study
- Migrating a .NET Framework Application to .NET Core: A Case Study
Most of real-world applications regularly undergo some large scale refactoring sessions for various reasons:
- Some business requirements change.
- An obsolete network, UI or database technology consummed must be replaced with a new one.
- Performance can be improved significantly with a different architecture.
- Code quality is so poor that any change or evolution takes a lot of resources.
One difficulty when planning a large scale refactoring is to analyze the impact on the code base.
- How large is the perimeter of the code impacted?
- How long it will take?
- Will it break some clients?
With its various features to explore and query the code NDepend can help a lot with impact analysis. Here are some common scenarios:
List classes that will be impacted by the refactoring
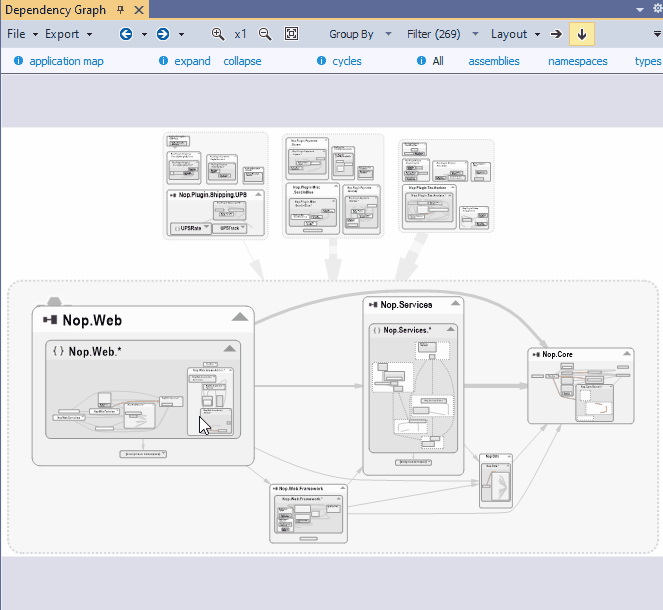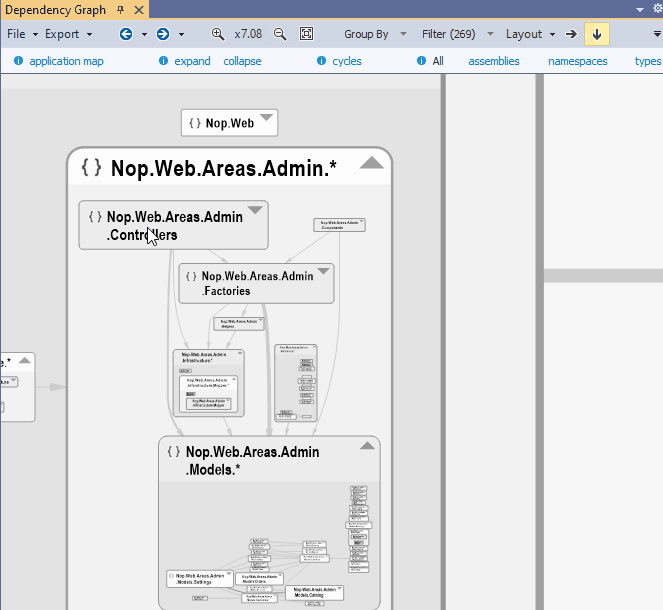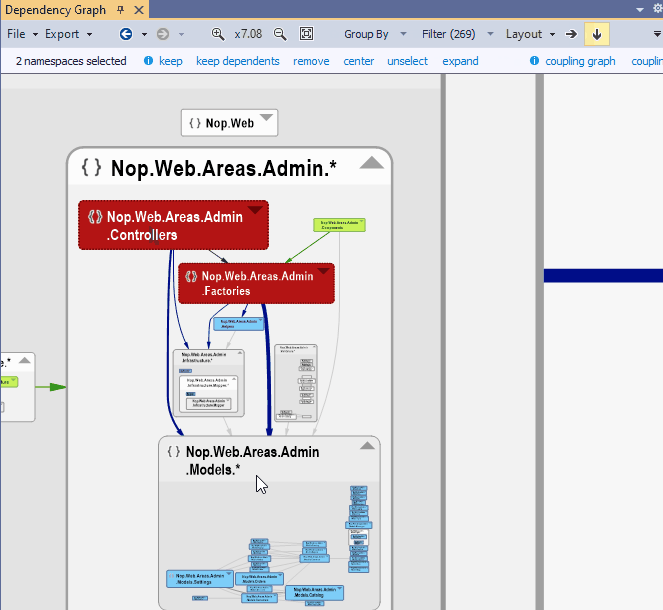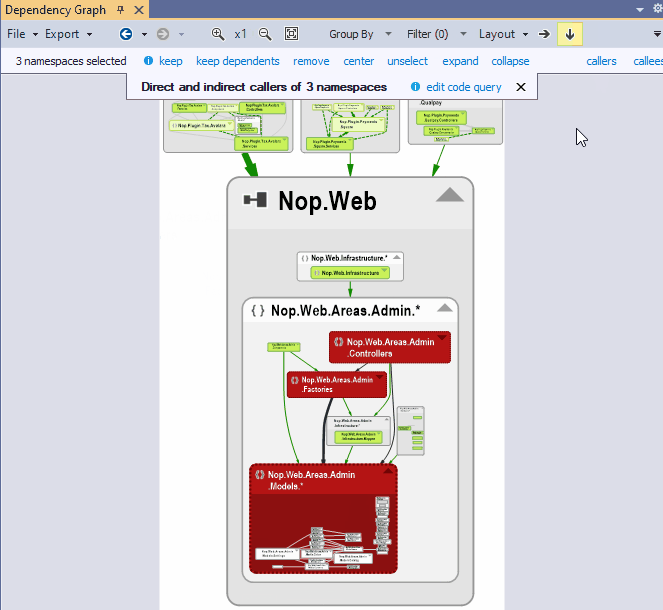
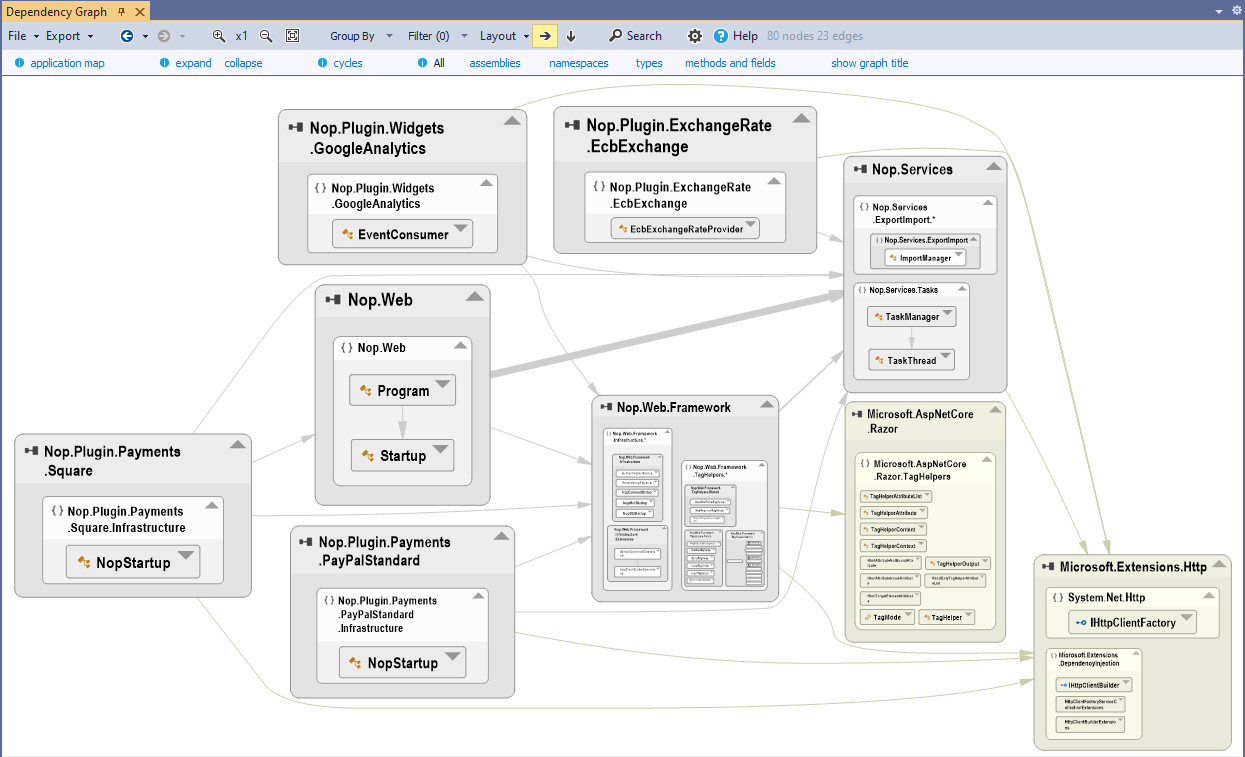
When you plan to change or replace some core components it is essential to list which component will be affected. To do so you can select one or several boxes in the NDepend dependency graph and click the link callers in the navigation bar. A new graph is then generated made of core components and affected components.
{kind=link}
Actually a code query is generated when clicking callers in the graph navigation bar. The generated graph gets a title and near the title you can click the link edit code query. The code result represents all affected components. For each affected component you get a depth metric that represents the depth of usage of the core component:
- N/A (Not Available) if the affected component doesn't rely on the core component.
- 1 if the affected component directly relies on the core component
- 2 if the affected component relies on another component of depth 1
- and so on...

You can write such code query directly yourself. This is needed especially if the core components to be refactored is a complex set not easily selectable on the graph.
For example to get all classes that depend directly or indirectly on the assemblies Microsoft.AspNetCore.Razor and Microsoft.Extensions.Http you can write this code query:
let metric = ThirdParty.Types
.Where(t1 => t1.ParentAssembly.FullName
.EqualsAny("Microsoft.AspNetCore.Razor",
"Microsoft.Extensions.Http"))
.FillIterative(t2 => t2.SelectMany(t3 => t3.TypesUsingMe))
from t in metric
select new { t.CodeElement, t.Value }
In the query result you can browse all those dependent classes:

You can export this query result with the button Export to Graph. This way you get the complete dependency graph made of assemblies that will be refactored or replaced and the classes that will be impacted by the refactoring.
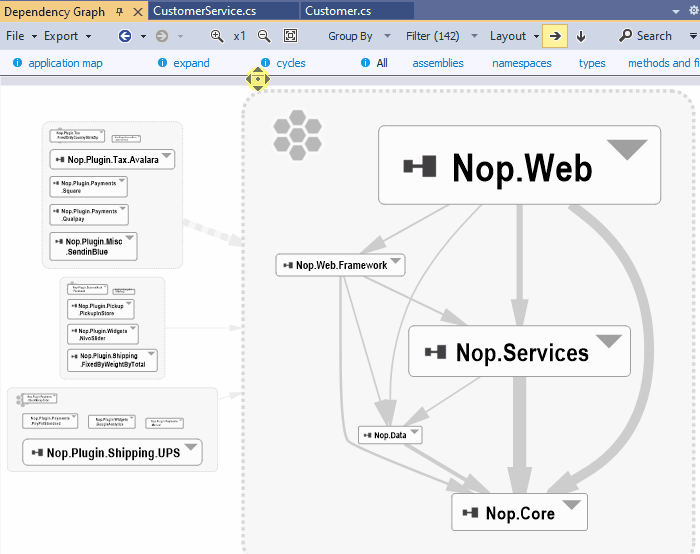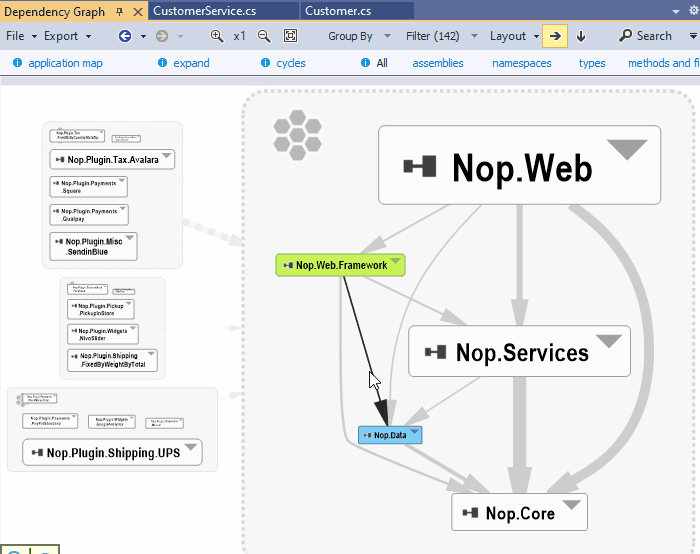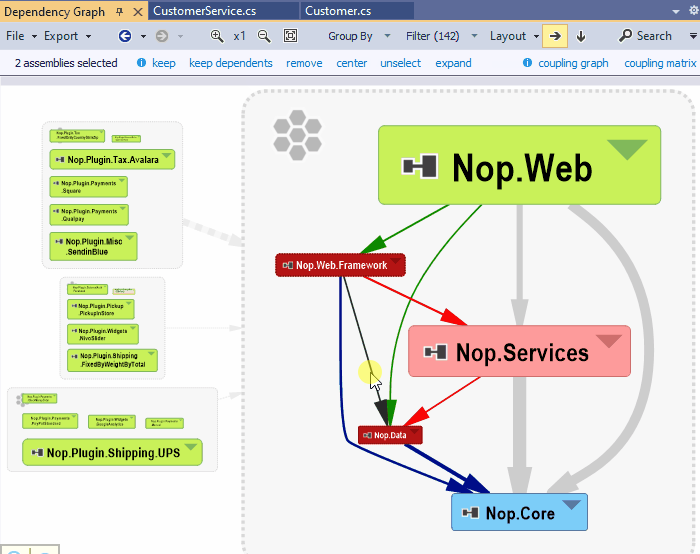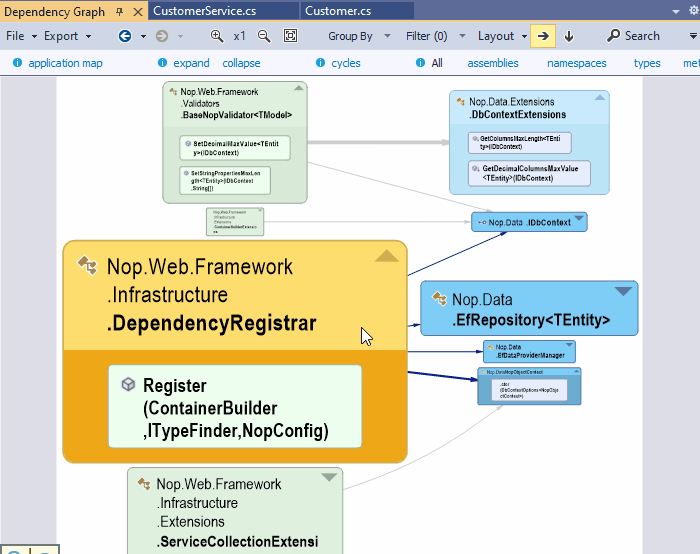
Visualize classes involved in the coupling between 2 projects
On the NDepend Project Dependency Diagram any edge can be double-clicked. Doing so generates a new graph made of classes and methods involved in the dependency represented by the edge.
{kind=link}
In fact when double clicking the edge a code query is generated to match all classes and methods involved in the dependency. This result set is then exported to the graph to generate the coupling graph. The coupling graph will help you. But sometime, in situations too complex to be well represented by the graph, the code query result will be more readable and detailled.

It can happen that you need to generate a coupling graph for 2 code elements not linked by an edge. For example an assembly using and an interface: Since types are grouped into their parent assemblies there is no edge in this situation.
A coupling graph can still be obtained: just select the 2 elements in the graph and you will see the coupling graph / matrix menus in the navigation menu.
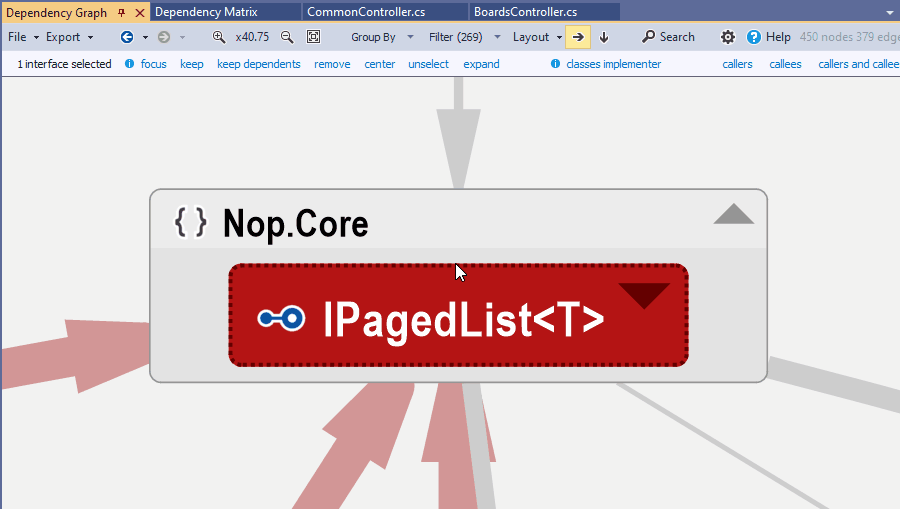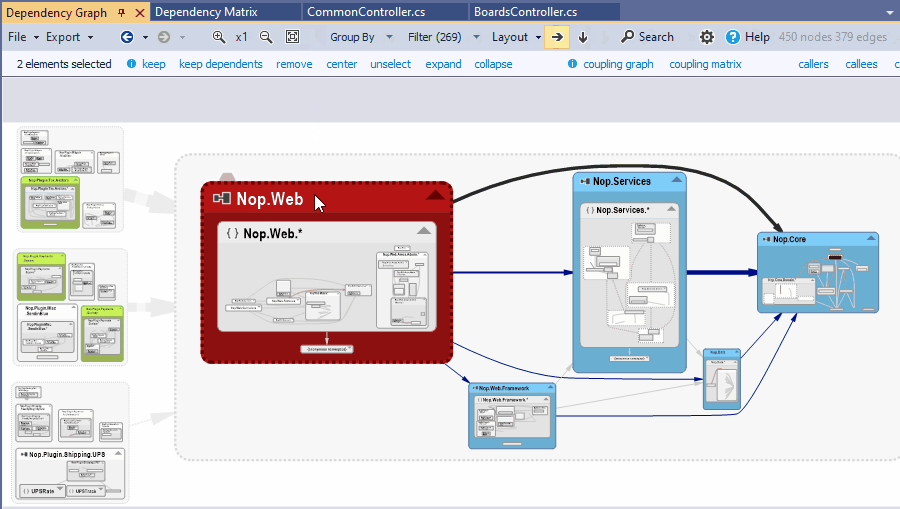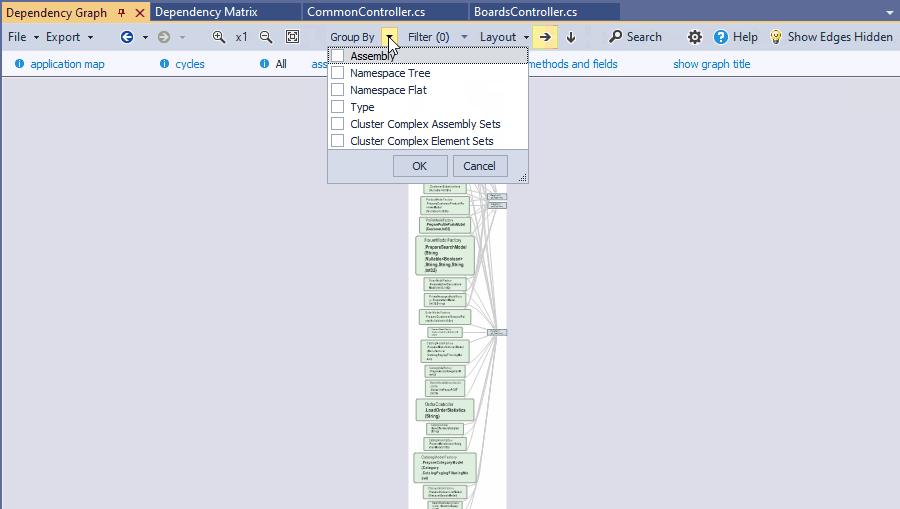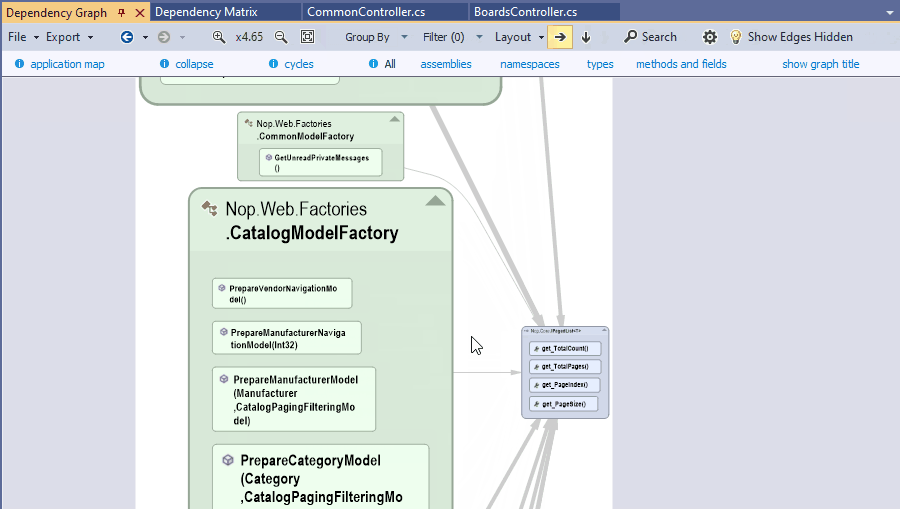{kind=link}
Tranform your monolithic code into layered code
If your refactoring concerns a monolithic portion of code, which is often the case, you will need first to transform it into layered code to be able to refactor it.
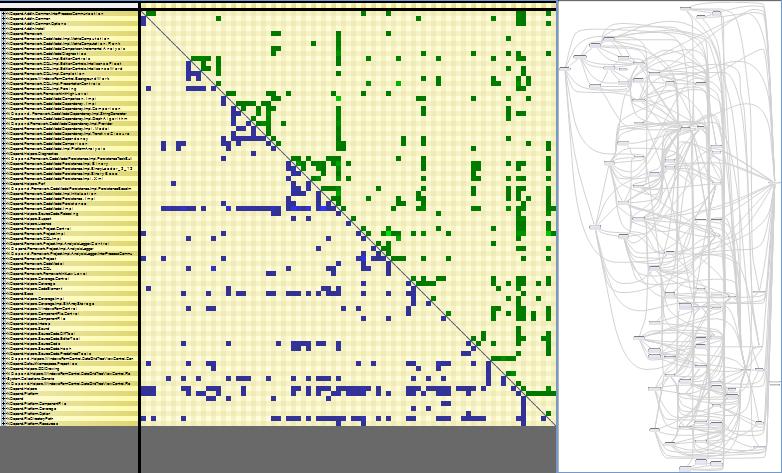
The NDepend Dependency Matrix can help identify cycles that forms monolithic components:
- Cells representing a bi-directional dependency have a background paint in black.
- The matrix triangularization heuristic aggregates elements involved in a cycle.
- Cycles are highlighted with a red border.

Also it is easy to assess if the code is layered with the matrix: in such case the matrix is triangularized.
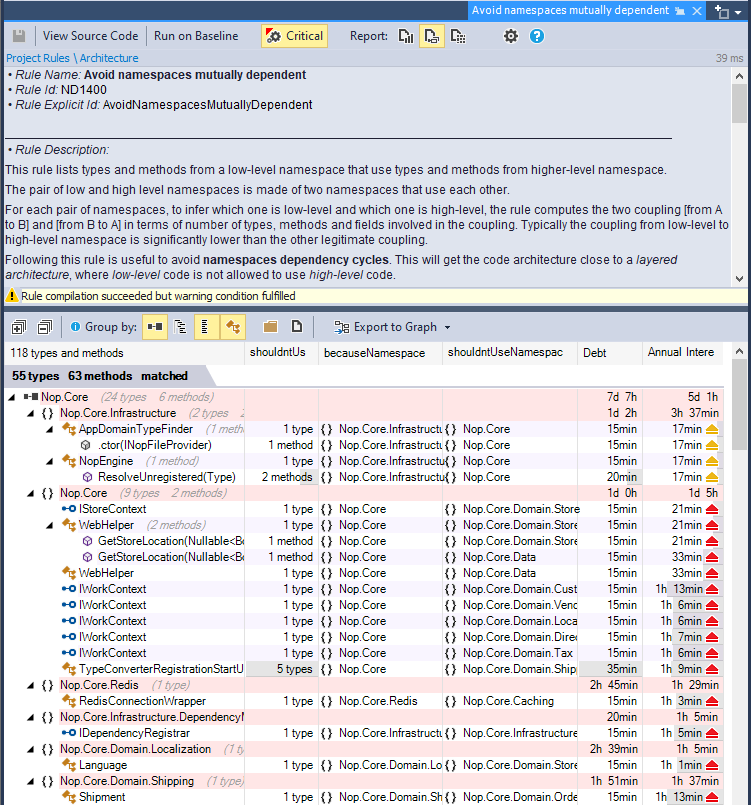
To get actionable advice and steps to transform monolithic into layered code you can refer to the default rule Avoid namespaces mutually dependent. This rule lists dependencies at class and method level, that must be discarded. It is then up to you to decide how to discard this dependency. Often you will need to move a type from one namespace to another or create an interface and rely on the Dependency Inversion Principle.
Split god class into a grape of smaller classes
Sometime the monolithic code to refactor concerns just one large and complex class that does too much: this phenomenon is named god class: a class that has grown with time to end up doing too much.
A god class must be partionned into smaller fine-grained classes. The difficulty is to define these classes in a way where both the states and the logic implemented in the god class methods fit well.
NDepend can help with that. For example by looking at the .NET class implementation of System.Globalization.DateTimeFormatInfo we can see it contains 113 instances methods, 45 instance fields, 12 static methods and 4 static fields. The source file contains almost 3.000 lines.
This class handles a dozens of display pattern (LongDatePattern, LongTimePattern, RFC1123Pattern...). In the real-world this class could certainly be well splitted into a grape of nested and private classes. And to do so the dependency matrix made of its methods and fields help. Thanks to the triangularization matrix heuristic we see emerging some squared parts. Each square is an indication of a highly-cohesive set of methods and fields that would fit well into their own class:

Notice that above we wrote: In the real-world this class could certainly be well splitted into a grape of nested and private classes. Improving the design this way by creating many smaller classes implies a small perfomance cost at runtime. And for .NET reference classes optimal performance is a requirement.
How to Plan Large-Scale Refactoring?
In this blog post How to Plan Large-Scale Refactoring? we explain how we use NDepend to plan some large-scale refactoring on NDepend itself.
Clean Architecture Refactoring: A Case Study
In this blog post Clean Architecture Refactoring: A Case Study we explain step by step how we use NDepend to refactor NDepend in order to migrate most non-UI code to .NET Standard.
Migrating a .NET Framework Application to .NET Core: A Case Study
In this blog post From Legacy to .NET 8: Migrating with NDepend Chun Li explains how to use NDepend to migrate a .NET Framework application to .NET 8.